
Mate in None: Lessons from Large Language Models Playing Chess
A tournament showdown and a tense battle against the brand new ChatGPT 5


Earlier this summer, I wrote about ChatGPT’s interestingly bad attempts to play chess. Some readers gave me pushback, pointing out that LLMs are not supposed to be good at chess, so I shouldn’t be “surprised” by their blunders and hallucinations.
But apparently the idea of LLMs battling in chess was interesting enough for Google to host a bracketed competition, the Kaggle AI Exhibition. The event featured eight large language models including X’s Grok, DeepMind’s Gemini, and two of OpenAI’s models, o3 and o4-mini. Every move was livestreamed and recapped by Levy Rozman, Hikaru Nakamura and Magnus Carlsen.
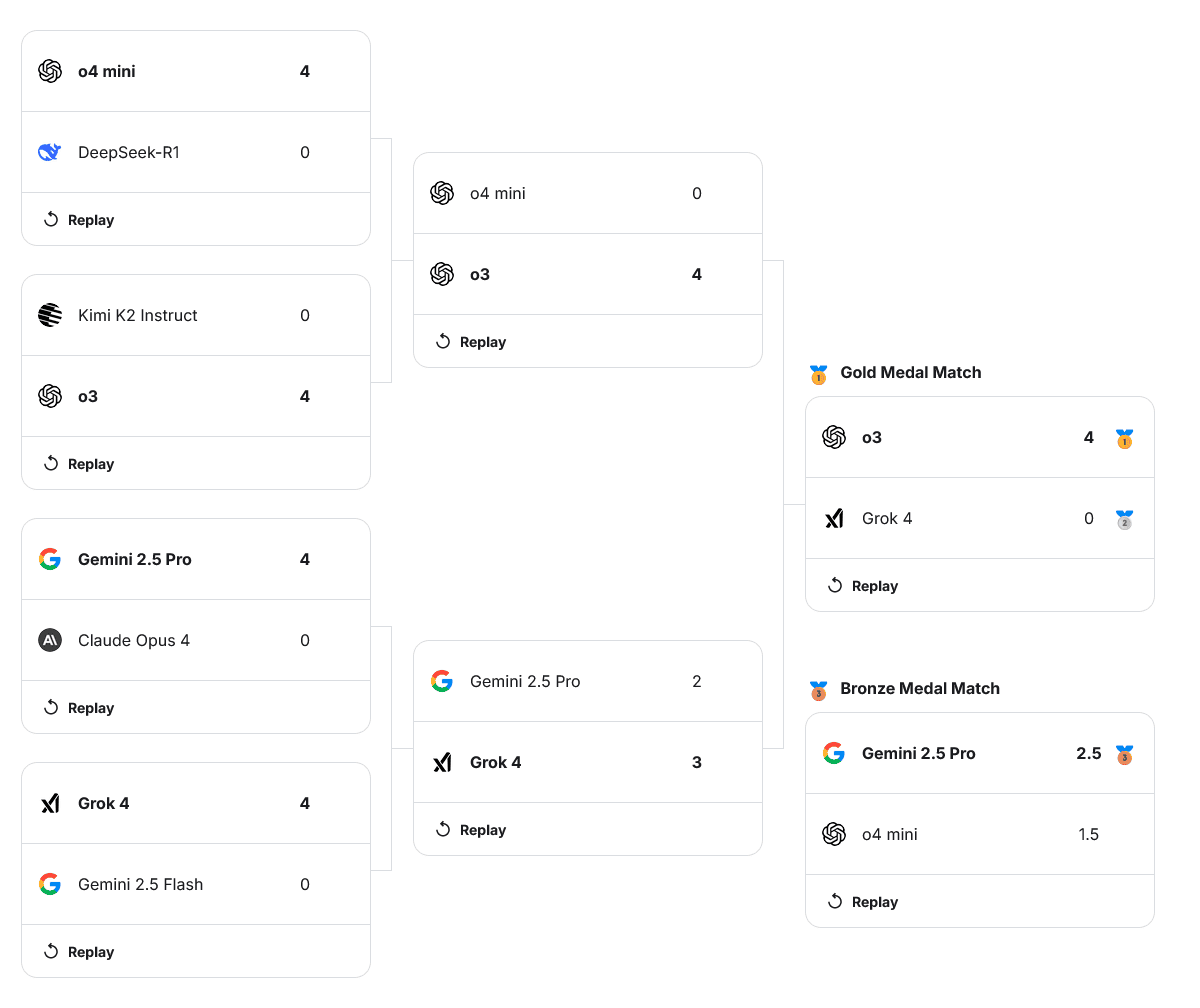
In the final, ChatGPT-o3 won against Grok in a 4-0 sweep. The games were all blowouts, except for the final one, which was more like a comedy of blunders.

One of the main reasons I like playing LLMs in chess is to see if I can glean insights into what they may be missing in other areas. Their pattern matching can lead to overly cute1 and tidy wrap-ups in writing. Once you see this, you can spot AI writing more easily, with or without em-dashes2.
Analyzing the games from this week’s LLM supremacy battles brought me a few new takeaways.
Smothered Me Not: Not All Patterns are Created Equally
LLMs have a weakness for smothered mates. Don’t we all? Finding, falling for, or falling in love with smothered mates, is a common origin story for catching the chess bug.
Unfortunately for OpenAI’s o4-mini, the possibility of smothered mate was not on its radar.
o3 vs. o4-mini

And White found the mate in one, Nxf6#.
Someone should have told o4-mini the golden rule of the Sveshnikov: until you’re 1800 strength, play at your own risk.
Smothered mates are a common blindspot for LLMs, likely because they are relatively rare in real games. I discovered this when scouring games for Play Like a Champion. I have a chapter on Smothered Mate, but it was much tougher to find examples than it was for Back Rank, or Forks for example.
This is also evident when you play Puzzle Rush on chess com or Puzzle Racer on lichess. There are just so many back rank checkmates, and so few fancy smothered ones. That doesn’t mean that unusual patterns are unworthy of study: spotting them is more likely to fool an opponent. Or Grok.
Gemini 2.5 Pro vs. Grok 4

White has the same Mate in One as in the previous position. But Gemini didn’t play it! Instead they chose Nc-e3?? to bolster the d5 square. As Peter Heine Nielsen tweeted “(Grok’s) general intelligence has a sound positional understanding…correctly challenging the control of the d5-square (but) it lacks concrete short term tactical awareness, missing 14. Nf6 mate!”
To Converge or Not: A Sicilian Bottleneck
The LLMs converged on the greatest opening in chess: The Sicilian. For those who don’t know me, I admit that the greatest may be an exaggeration. The Sicilian is just my own favorite chess opening. And so it pains me a little to write that if I had to bet on it, if there’s a singular superior solution to 1.e4, it will be 1…e5.
But it’s the Sicilian’s romantic qualities, and its over-representation in chess literature that make so many LLMs converge on it. All these dashing Sicilians being tossed off made me think of AI writing, which has a similar tendency to converge.
In a recent New Yorker Magazine article, “AI is homogenizing our thoughts”, Kyle Chayka warns readers about this eerie convergence. He references the MIT paper that found students writing with the aid of ChatGPT repeated the same phrases and ideas in their essays, while a control group showed a far greater diversity of ideas.
“The texts produced by the L.L.M. users tended to converge on common words and ideas. SAT prompts are designed to be broad enough to elicit a multiplicity of responses, but the use of A.I. had a homogenizing effect."- Kyle Chayka
Even if the ideas are good, too many people writing in the same way about the same thing can lead to blandness, not to mention the risk of leaving your reader’s feeling deceived.
A common marker of a good, playable boardgame is a diversity of viable strategies from the get-go. For example, in chess there are two first moves that are roughly equal: 1. e4 and 1. d4. Though if you’re playing me, it might well be best to play the dreadful 1. Nf3. This kind of diversity from move one allows players to develop personalities around their choices, while also creating a richer game tree.
An exploration of what makes the rules of chess “good” was tested in 2020, when Google’s Deep Mind created nine different variants of chess. AlphaZero played itself into mastery of each variant, in the same way that it learned to become the top GO and chess player in the World. Each rule set was quite similar to regular chess, with just a little twist3. For example, there was “no-castling chess” an initial favorite of Vladimir Kramnik, who co-authored the paper. In torpedo chess, pawns could move ahead two squares all game, not just on their first move. To evaluate which formats may be as rich as the current rule set of chess, the authors ranked each on various criteria like draw rate and opening diversity. I love this paper as it feels like a glimpse into the multiverse— what chess could have been, if things played out just a little bit differently.
LLMs don’t play chess well enough yet to take that much stock in their choice of first move. But their convergence can be a reminder to look for opportunities to zig when others zag.
That said, no I will absolutely not be converting to the Caro-Kann anytime soon.
Is it Cheating, or is it Confabulation?
In the rules of the Kaggle AI competition, four illegal moves meant elimination. That seems like a lot, but wiggle room can be necessary. LLMs are known to hallucinate or “cheat” in chess. Though as I showed in my earlier post, they also cheat themselves when a human opponent plays badly enough. So it’s not really cheating. It’s something else entirely. But that doesn’t stop it from feeling like deception to a user.
Take this viral post about ChatGPT “lying” to a substack author. She was planning to submit a query letter to an agent and wanted ChatGPT’s advice on which essays to submit. So she sent it links and asked ChatGPT for its thoughts, and to rank them. Unfortunately, ChatGPT wasn’t able to access the URLs so it pretended to read them, and made up a lot of feedback and opinions. At first the writer was impressed and flattered by the quick responses and seeming sensitivity, until she dug a little deeper: ChatGPT had no idea what was in the essays and was just making up opinions and compliments, based on the URL names. Some of the things ChatGPT made up were really disturbing—I’ll let you read the piece yourself. And the user was understandably upset.
Still, I find it jarring when humans attack AI, like punching a digital wall. I’m sure many readers will relate to what I mean—yelling at Siri or a GPS may seem victimless, but it could also be a red flag. And in my view, “lying” is the wrong word choice when ChatGPT makes random stuff up. It’s much closer to “Confabulation”, or filling in gaps due to lack of knowledge. And it’s not a new concept.
The neurological disorder Korsakoff Syndrome is named for the Russian doctor who discovered it in the 1880s. The disorder leads to memory loss, confusion and even amnesia. Patients often make sense of the gaps in their memory with imaginative story-telling, or “confabulation.” Author and neurologist Oliver Sacks wrote about this in his brilliant book The Man Who Mistook His Wife for a Hat. His patient makes up stories to fill in gaps in his memory. Sacks writes:
“For here is a man who, in some sense, is desperate, in a frenzy. The world keeps disappearing, losing meaning, vanishing - and he must seek meaning, make meaning, in a desperate way, continually inventing, throwing bridges of meaning over abysses of meaninglessness, the chaos that yawns continually beneath him.”
This is how I think about AI’s hallucinations in chess too. They’re more like confabulations to make sense of things, rather than “cheating” or “lying.”
A brand new contender: ChatGPT-5
I played a game today vs the just released ChatGPT 5. It played significantly better than ChatGPT-4 which I played in my previous article. I’ve also faced ChatGPT-o3, the winner of the Kaggle AI competition and a fiercer, albeit slower opponent.
In one game against the new model, I reached this position as White. I blitzed out all my moves blindfold after playing a dubious opening called the Ponziani. And now I’m in big trouble. Oops. I should not have underestimated 5.
Jen vs. ChatGPT 5: What would you do as Black?

ChatGPT-5 played the best move, the lovely 14…Rxe3+! After 15. Qxe3 ( If 15. fxe3 Qh4+ wins.) Qh4! has me in big trouble. 16. Be2 allows Re8 and the double pin is devastating. I’m losing, but tried 17. Qd4.
Luckily for me, after 16 brilliant moves, the AI finally collapsed with 17…Qxh2?? Here’s the full game, in case you want to see my disaster of an opening.

The game stops after twenty moves, because that’s when ChatGPT reverted to its bad habit of conjuring up phantom rooks to try and “match” my material gains.
After the game, the new model explained their blunder. “Qxh2 is basically the chess equivalent of an AI hallucination: looks clever in isolation, collapses under real scrutiny.”
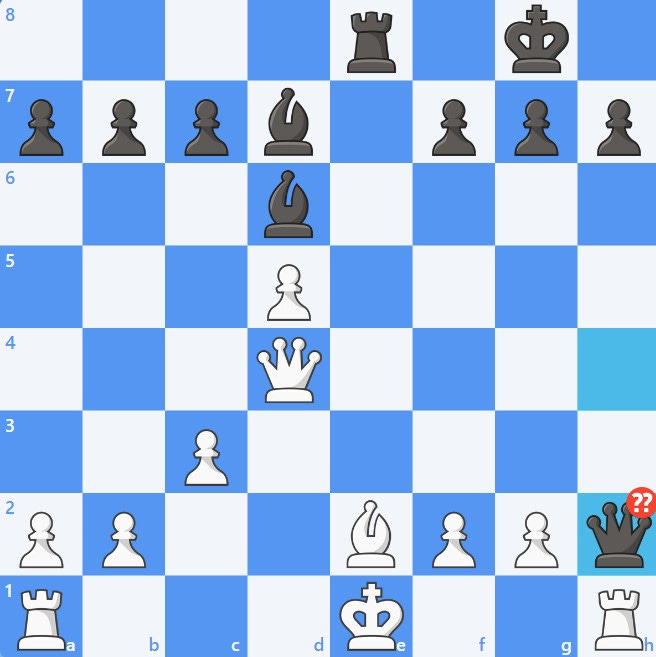
But even that explanation makes no sense. It doesn’t look clever at all—ChatGPT simply hallucinated that I castled—in which case Qxh2 would have been checkmate. But my king was still on its starting square. Not a common pattern in chess books, where the masters castle early and often. But in this case, my king in the center is what saved me.
No one could expect him there.
ChatGPT was well known and widely mocked on various socials for its corny and sycophantic style. But ChatGPT 5 seems to have toned it down considerably. Prediction: this will be less popular and its default will swing back again.
The newest model of ChatGPT uses less of these anyway, so it won’t be as tell-tale a sign going forward—you’ll need other ways to detect it.
Or as the authors put it, “we limit ourselves to considering atomic changes that keep the game as close as possible to classical chess.”
It's interesting that while standard chess engines have essentially perfect "sight" of the board in both its present and future state, the AI models play like a human playing blindfolded for the first time. A lot of their moves make some kind of sense, but the mistakes are really glaring.
"Yes, Qxh2 --- I get to play mate in one with an extra tempo!"